Unter Named Entity Recognition (NER) versteht man das automatische Erkennen von Personen-, Orts- oder Organisationsnamen in Texten. Named Entity Recognition ist ein wichtiger Baustein zum Verständnis von Texten mithilfe künstlicher Intelligenz und für Anwendungen in den Bereichen
- Informationsgewinnung und automatische Verschlagwortung von Texten,
- Chatbots und digitale Assistenten,
- Anonymisierung von Dokumenten.
Das folgende Bild zeigt dies für einen einfachen Text über die Fachhochschule Südwestfalen:
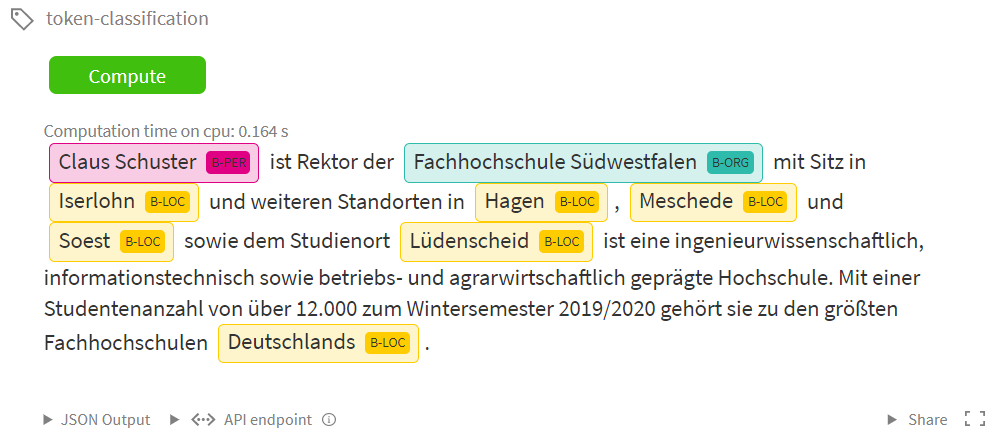
Die aktuell besten Verfahren für NER basieren auf neuronalen Netzen mit der sogenannten Transformer Architektur (s. Ashish Vaswani et al.: Attention is All You Need oder Wikipedia). Das von Google AI entwickelte BERT (BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding) war das erste derartige Modell, das Transfer Learning ermöglicht: Ein Basismodell wird mithilfe großer Mengen Text trainiert. In einem zweiten Schritt wird das Modell mithilfe von Trainingsdaten für eine konkrete Aufgabe wie etwa die Textklassifikation “nachtrainiert”.
Der beste frei verfügbare Trainingsdatensatz für NER in deutschsprachigen Texten stammt aus dem Wettbewerb GermEval 2014 (s. Darina Benikova, Chris Biemann and Marc Reznicek: NoSta-D Named Entity Annotation for German: Guidelines and Dataset).
Mithilfe dieser Trainingsdaten haben wir das deutschsprachige BERT-Modell bert-base-german-dbmdz-cased und ein deutschsprachiges Electra-Modell electra-base-german-uncased für die Named Entity Recognition trainiert. Das BERT-Modell kann bereits unter huggingface.co/fhswf/bert_de_ner heruntergeladen oder live ausprobiert werden. Das noch etwas bessere Modell auf Basis von Electra (s. Bild oben), das auf dem Testdatensatz von GermEval 2014 einen F1-Score von 87% erreicht, werden wir in Kürze veröffentlichen.